ZFS and Intelligent Storage
It's been almost 10 years to the day since Sun Microsystems first released ZFS as a part of the Solaris 10 6/06 release. I worked for Sun at the time, and it was clear that ZFS was a revolution in file systems - but it was also very clear that it was a filesystem designed for the world that Sun lived in.
Throughout it's history, Sun struggled with storage, and there was really only one storage device they managed to make themselves (as opposed to rebadge or resell) - the JBOD! Whether it was an SSA112 (30 disks, each of them 2GB, for a total of 60GB storage! Yes, GB!) or a "Thumper" (Sun X4500, released at basically the same time as ZFS with up to 48x 2TB disks) the one thing all Sun storage products had in common was the lack of an intelligent controller.
For this world, ZFS was (and, potentially, still is!) the perfect product. It could take any number of JBOD disks, of any size, and do what no storage arrays of the time could - intelligent data protection, compression and deduplication, snapshots, replication, and so much more.
However fast forward to 2016 and JBOD storage arrays have almost no place in enterprise storage. Most of the smarts that used to be done at the host level are now done natively by far more intelligent storage arrays, so we rely far less on the OS or host-level software to handle these functions for us.
More importantly, ZFS data storage strategy conflicts with the functionality of modern storage, to the extent that it impacts or negates entirely many of the benefit of these intelligent arrays, such as thin provisioning, deduplication, compression and snapshots.
Thin Provisioning - ZFS v's UFS v's RAW
For this test I created 3 LUNs on an XtremIO array, and presented them to a SPARC host running Solaris 11.3. Each LUN was 1TB in size, but like most modern arrays the LUNs on XtremIO are thin provisioned by default, so they started out using 0 bytes of space (as per the "Space in Use") column :
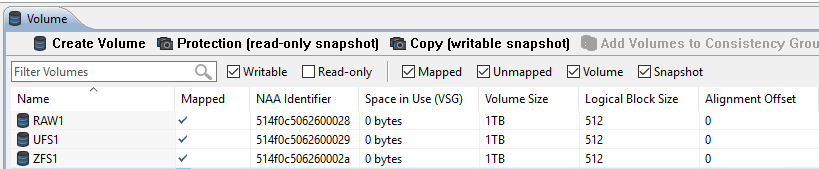
On one of these LUN I created a ZFS pool. In order to best represent a database-style use case I set the ZFS recordsize to 8KB, and confirmed that ZFS compression was disabled.
On the second LUN I created a UFS filesystem using the entire disk. Defaults were used for all options except for setting the fragment size to 8k, and only allocating 1 inode for every 2MB of space.
The third LUN was simply partitioned to allocate the entire space to one slice, in much the same way as you would if it was to be used by something like Oracle ASM.
After this initial setup, all of the LUNs showed a small amount of space used, with RAW using the least (just enough to store the partition table), and UFS using the most at just over half a GB.
Writing 50GB
The next step was to write 50GB worth of data to each device. For ZFS and UFS, this was done by telling Vdbench to create a 50GB file on them, which it will then fill with random data. Note that whilst the Vdbench config file below shows a very short read workload, this is prefaced by Vdbench actually setting up the two files we've asked for which is the real purpose of this step.
sd=sd1,lun=/zfs1/zfs50G,size=50g
sd=sd2,lun=/ufs1/ufs50G,size=50g
wd=zfs1,sd=sd*,xfersize=8k,rdpct=100,seekpct=100
rd=zfs1,wd=zfs1,iorate=max,interval=1,elapsed=2
For the RAW device there is no concept of a file, so instead Vdbench was used to write out a stream of data filling the first 50GB of the raw LUN :
sd=sd1,lun=/dev/rdsk/c0t514F0C5062600028d0s0,size=50g
wd=raw1,sd=sd*,xfersize=128k,rdpct=0,seekpct=eof
rd=raw1,wd=raw1,iorate=max,interval=1,elapsed=9999
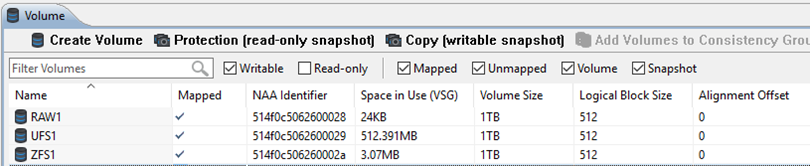
After both of these jobs had been run, all three LUNs showed around 50GB of space use on the array as expected
From the OS level, the two filesystems also showed around 50GB of space used.
# df -h /zfs1 /ufs1
Filesystem Size Used Available Capacity Mounted on
zfs1 1000G 51G 949G 6% /zfs1
/dev/dsk/c0t514F0C5062600029d0s0
1023G 50G 963G 5% /ufs1
Overwriting 50GB
The next step was to overwrite that 50GB of data. For the two filesystems, this was done by modifying the data within the existing files. ie, no new files were created, only the existing 1 file was modified - exactly like what would happen if using these files for a database.
Once again, Vdbench was used, this time asked to do a single sequential write of the 50GB files and raw device. (The "seekpct=eof" option tells Vdbench to overwrite the data exactly once, from start to end)
sd=sd1,lun=/zfs1/zfs50G,size=50g
sd=sd2,lun=/ufs1/ufs50G,size=50g
sd=sd3,lun=/dev/rdsk/c0t514F0C5062600028d0s0,size=50g
wd=ow-seq-zfs,sd=sd1,xfersize=8k,rdpct=0,seekpct=eof
wd=ow-seq-ufs,sd=sd2,xfersize=8k,rdpct=0,seekpct=eof
wd=ow-seq-raw,sd=sd3,xfersize=8k,rdpct=0,seekpct=eof
rd=ow-seq-zfs,wd=ow-seq-zfs,iorate=max,interval=1,elapsed=9999
rd=ow-seq-ufs,wd=ow-seq-ufs,iorate=max,interval=1,elapsed=9999
rd=ow-seq-raw,wd=ow-seq-raw,iorate=max,interval=1,elapsed=9999
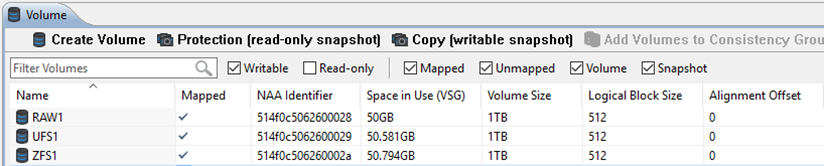
Given that we are just overwriting existing data here, the obvious expectation is that this would not require any additional storage - it would just use the storage that is already assigned to it.
At the host level, this is exactly what occurred, and no additional space was used within either the ZFS or UFS filesystems :
# df -h /zfs1 /ufs1
Filesystem Size Used Available Capacity Mounted on
zfs1 1000G 51G 949G 6% /zfs1
/dev/dsk/c0t514F0C5062600029d0s0
1023G 50G 963G 5% /ufs1
However looking on the array side, we see something very different.
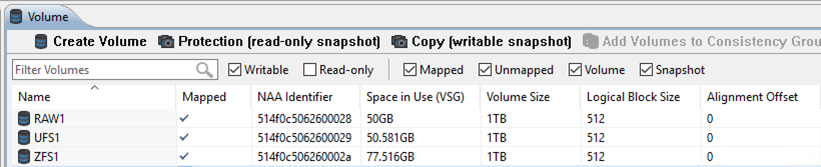
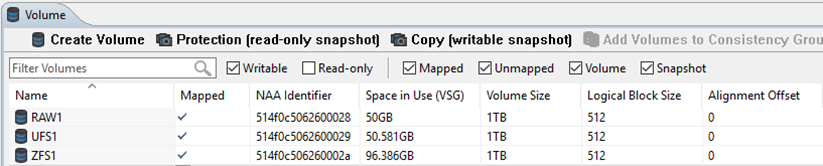
The utilization for the Raw device and the UFS filesystem has not changed. However the space used by the ZFS filesystem has grown over 50% - despite the fact that we're still only storing 50GB of data, ZFS has written data to over 77GB of disk space!
Repeating the same 50GB overwrite test increases the space used by ZFS even further - to 88GB on the next run, and 96GB on the third run - whilst the space used by the RAW and UFS devices didn't change at all.
Next I change the workload slightly - instead of being a fully sequential write, I changed it to a fully random write - keeping the volume of data overwritten at 50GB per LUN.
sd=sd1,lun=/zfs1/zfs50G,size=50g
sd=sd2,lun=/ufs1/ufs50G,size=50g
sd=sd3,lun=/dev/rdsk/c0t514F0C5062600028d0s0,size=50g
wd=ow-seq-zfs,sd=sd1,xfersize=8k,rdpct=0,seekpct=100
wd=ow-seq-ufs,sd=sd2,xfersize=8k,rdpct=0,seekpct=100
wd=ow-seq-raw,sd=sd3,xfersize=8k,rdpct=0,seekpct=100
rd=ow-seq-zfs,wd=ow-seq-zfs,iorate=max,interval=1,elapsed=9999,maxdata=50g
rd=ow-seq-ufs,wd=ow-seq-ufs,iorate=max,interval=1,elapsed=9999,maxdata=50g
rd=ow-seq-raw,wd=ow-seq-raw,iorate=max,interval=1,elapsed=9999,maxdata=50g
This time the results were even more pronounced! RAW and UFS were once again unchanged, but the space used by the ZFS LUN increased by over 80GB up to 177GB.
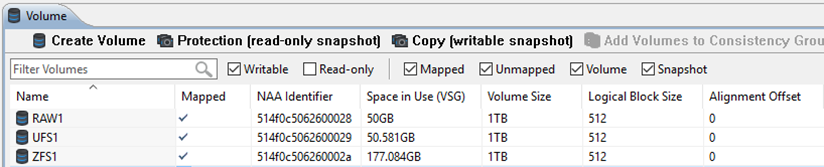
A subsequent run of the same test pushed this even high, using another 72GB of space for a total space in use of 249GB - all to store 50GB of data!
But Why?
Why is ZFS using 250GB of space to store only 50GB of data? The simple answer is that it's not - it's only currently using around 50GB of that space - but it has failed to tell the array that it's done with the remaining 200GB.
ZFS is, much like XtremIO, a “Write Anywhere” data layout (with a log-structured-style layer added on top called the ZIL, short for ZFS Intent Log). When you overwrite a block on data at the filesystem level, the new block doesn’t doesn’t get written in the same place as the old block, but instead gets written into free space somewhere else, metadata gets updated, and then in time the old block may be deleted or reused.
This results in exactly what we've seen above - significantly more space being used at the storage level than at the host as ZFS in effect ends up keeping multiple (outdated/unusable) versions of each block of data and only overwriting them at a much later stage. There are also a number of flow-on effects on array-level data reduction technologies like deduplication and compression due to the inability of the array to clear unique data that is no longer required.
This model works perfectly in the type of array that ZFS was designed for - a JBOD of spinning disks, where those disks are completely owned and managed by ZFS. ZFS is tracking which space is used and which is not, and when it needs to it'll come back and re-use it. It fails miserably in today's world of flash-based storage and intelligent, thin-provisioning storage arrays.
UNMAP to the Rescue
The good news is that there exists a mechanism for ZFS to notify the array that it no longer requires the space that it has "overwritten", and thus allow the array to reclaim that space - the SCSI UNMAP command (sometimes referred to as TRIM).
By sending UNMAP/TRIM commands, ZFS can notify the array that a particular block of storage is no longer required, which on most arrays will trigger the array to re-thin-provision that block of storage, freeing the space it was using.
Unfortunately that's where the good news ends. Solaris/ZFS added support for UNMAP in the Solaris 11.1 release, however their implementation was so horribly broken that they recommended disabling it in the release notes for the very same version! In a release soon after they disabled it by default, and despite it now being almost 4 years and 2 Solaris release later, they still do not recommend ever turning it on.
I don't mind living on the edge, so I decided to turn on UNMAP and re-run my testing. The recommended way to enable UNMAP is to add to the follow to /etc/system, which allows ZFS to UNMAP blocks of 1MB or larger - which seems very large to me (to put this in perspective, XtremIO thin provisions at an 8K block size)
set zfs:zfs_unmap_ignore_size=0x100000
After a reboot and a quick "adb" to confirm that unmap was enabled, I cleared the entire LUN and re-ran the same tests above (this time for ZFS only). The initial fill left me at just over 50GB, same as before :

After one overwrite at 75GB (previously this was 77GB) :

And after two overwrites at almost 95GB (previously just over 96GB) :

Whilst there is a slight improvement here, I suspect it just comes down to the non-deterministic space allocation rather than an actual improvement due to UNMAP.
Attempting to do a random overwrite was far less successful. A few seconds into the test all IO to the array stopped, and Solaris reported an error :
SUNW-MSG-ID: ZFS-8000-GH, TYPE: Fault, VER: 1, SEVERITY: Major
PLATFORM: SUNW,Sun-Fire-T200, CSN: 11223344, HOSTNAME: solaris
SOURCE: zfs-diagnosis, REV: 1.0
EVENT-ID: 51107047-6439-4b07-9ca8-b200a9d59341
DESC: The number of checksum errors associated with ZFS device 'id1,ssd@n514f0c506260002a/a' in pool 'zfs1' exceeded acceptable levels.
AUTO-RESPONSE: The device has been marked as degraded. An attempt will be made to activate a hot spare if available.
Re-formatting the LUN and starting all over again gave exactly the same results - a few minutes into the random workload the pool once again reported data corruption - confirming Oracle's advice that turning on UNMAP for ZFS is not a good idea!
How About Snapshots?
Fairly clearly, ZFS's "write anywhere" approach largely negates the benefit of thin provisioning - but what if you weren't planning to rely on thin provisioning anyway? Especially in a database environment it's not uncommon to allocate only the amount of space that is going to be used by the database, with little to no additional free space in the filesystem.
Fundamentally this is a bad idea with ZFS, as it means that your zpool will be running near to 100% full - which can have a significant impact on performance (due to a lack of free space to "write anywhere" to) and can cause massive fragmentation which helps make performance even worse. But lets ignore that for a moment...
Array-level, space-efficient, thin-provisioned snapshots (like those implemented by XtremIO) have become a very popular means of taking copies of data, especially for databases. Those copies may then be used for multiple use cases including backups, analytics, or even development/test/QA environments. Implemented correctly, these snapshots have the advantage of having very low space requirements - the only incremental space required is for blocks that are modified on the source LUN (or the target LUN, for a read/write snapshots).
Normally additional space is only required the first time a block is overwritten after the snapshot is taken. Repeatedly overwriting the same block on the source LUN will not require any additional space, as there is no need to store the intermediate copies of those blocks - only the data when the snapshot was taken, and the current data need to be stored.
However in the same way that ZFS's write-anywhere approach impacts thin provisioning, it will also impact snapshots. Each new block that is written - even if it's an overwrite of an existing block - will be written to a new location so the array will see it as a new write, rather than an overwrite. This results in a much higher number of modified blocks, resulting in more space being required to store the snapshots - just like it was with thin provisioning.
This is especially obviously with database transaction logs where data may be overwritten dozens or even hundreds of times between snapshots. Normally at most one additional copy of the data in the transaction logs must be stored by the snapshots, however when ZFS is being used this could be hundreds of times as much data due to the lack of true overwriting of data.
The Real Solution
There's really only 2 way to solve this problem :
-
Don't use ZFS
-
Go back to JBOD's with the spinning disks that ZFS was designed for (and no, you can't use JBOD's with Flash as they will suffer from the lack of UNMAP support too!)
There is a potential third option, which is attempt to get Oracle to fix the issues with ZFS. Unfortunately, this seems unlikely to occur. Despite good progress being made in the OpenSource versions of ZFS, development of the Solaris version has stalled to the point where it's clear Oracle has no interest in improving it any further.
Which really leaves only one viable option - don't use ZFS. It's a filesystem designed for a world we no longer live in.