Flash testing tools - Diskspd
Some time ago I wrote about Microsoft's storage performance testing tool SQLIO, with the conclusion that it was unsuitable for using with flash-based products as it wrote nothing but zeros, which will not be stored by flash but instead treated as if they were an UNMAP/TRIM request.
It seems that Microsoft agrees, and has superseded SQLIO with their newer tool Diskspd. But is Diskspd really any better?
Looking through the documentation there are a lot of positive signs - in particular a -Z option that causes the "write source buffer [to be] initialized with random data, and per-IO write data is selected from it at 4-byte granularity" which sounds like it should overcome SQLIO's main issue of writing zeros.
Unfortunately passing the -Z option appears to do absolutely nothing. Running diskspd using that option, and then using the frhead hex editor shows that is is exactly the case - it's simply repeating the same 256 characters over and over for the entire size of the file :
Command Line: diskspd -b8K -c128M -d10 -o8 -t8 -Z128M testfile.dat
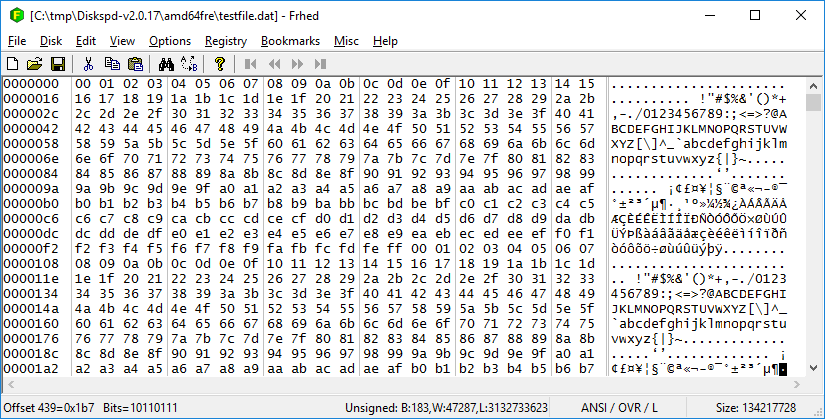
Where's the Random Data?
So what happened to the random data that the -Z option was supposed to generate?
Thankfully Microsoft has open sourced diskspd and put it on github, so it's possible to look at the code and see why the -Z option didn't work - and the reason is both quite simple but also quite baffling...
Put simply, the random data will only be used for writes carried out during the actual test phase of the run - NOT during the initial file creation. The existence of this option implies that the authors knew that random data was important for testing, yet they seem to have completely ignored that fact during the initial file creation.
Re-running the test above with a sequential 100% write workload, and a test that ran for long enough that it should have completely overwritten the test file with new data gave very different results - after the test the entire file was filled with mostly random/unique data (about 60% of all blocks were unique, 40% were repeated up to 5 times)
Command Line: diskspd -b8K -c128M -d30 -o8 -t8 -Z128M -w100 -si testfile.dat
In order to get closer to fully unique data (like the type of data you'd see for a database workload) it appears you would need to configure the write source buffer (-Z) to be a multiple of the size of the file you're testing against. Whilst this might be possible for a small test file like I've used above, it becomes impossible if wanting to test across the terabytes of space that would be required to get a valid test on an array that includes caching due to the memory required to store the buffer in.
Conclusion
Microsoft has made some improvements with the move from sqlio to diskspd, and whilst it's now potentially a worthwhile tool for testing standalone flash-based storage, it's still not an option for intelligent storage - specifically those that dedup data. Even though you could potentially overcome the deficiencies in its initial test file creation, the memory requirements needed to get it to generate random data for write testing are extreme (at least four times the file being tested) making it an unsuitable tool for testing on these types of arrays.