When Testing Tools Attack!
The nature of synthetic testing tools is that they are normally attempting to simulate some form of real-world workload, without actually having to have an entire environment setup to generate a real workload. The key word there is "simulate" - the traffic patterns they are using are very rarely exactly the same as for the workload they are simulating, but are instead a proxy workload that is presumed will give the same results as the real workload.
Unfortunately there are often cases where the mechanisms used to simulate traffic differ enough from real-world workloads that, whilst they may appear to be generating real-world situations, are actually doing something completely different.
A great example of this is the vdbench "rhpct" and "whpct" options. These two options allow you to specify a "read hit" and "write hit" percentage for traffic being generated. Vdbench will then attempt to generate traffic patterns that will cause the array to match the read and write cache hit percentages specified. It does this by focusing the requested percentage of traffic over a very small area of the LUN - 1 MB by default - and the remaining traffic over the rest of the LUN, with the expectation being that the 1MB of data being repeatedly read/written will end up locked in cache - and indeed this is generally what will happen on all arrays.
Whilst this works fine in terms of simulating the requested cache hit ratio, the traffic that is being generated is now completely atypical for a real environment - a cache hit rate of 50% will mean that fully half of the traffic being written/read will be going to/from a single 1MB range, which is something that would never actually happen in a real-world environment.
And for most arrays, this might not matter. But for some, including XtremIO, it does!
One of XtremIO's core design philosophies is "balance". Requests are balanced across all cores, all storage controllers, all paths, and all SSDs. One of the mechanisms used to obtain this balance is the natural "randomness" of storage, both in terms of the data itself, but also the natural distribution of data across a disk. To this end, we distribute requests across all cores in all storage controllers by breaking out the LUNs being presented to a host into 1MB segments, with the first 1MB segment being handled by the first core on the first storage controller, the 2nd 1MB by the second core on that storage controller, the 3rd 1MB by the first core on the second storage controller, and so on - looping back to the first core when we run out of storage controllers.
Given the natural random-ish nature of the requests, this results in a near perfect random distribution across all cores, giving the perfect balance that we desire. Or at least, it normally does.
You can probably already see where this is going! XtremIO splits between storage controllers based (in part) on 1MB chunks of the LBA. VDBench rhpct/whpct sends requests to a single 1MB chunk of the LBA. The end result is a very unbalanced system :
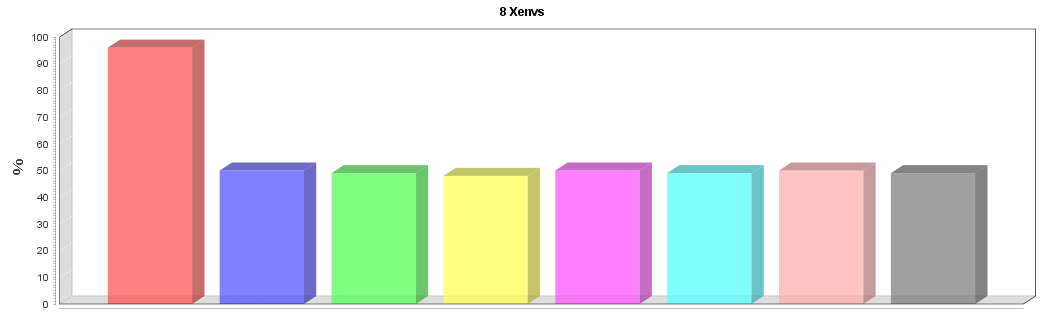
Notice how one single CPU core is much busier than the others? That's with a rhpct of 75%, so 75% of requests are being serviced by one core, with the other 7 cores only handling 25% of requests. Thankfully the LBA split only controls the balancing of one part of the XtremIO request, so the imbalance isn't as bad as it could be - but it's still enough that latency and maximum IOPS will be impacted.
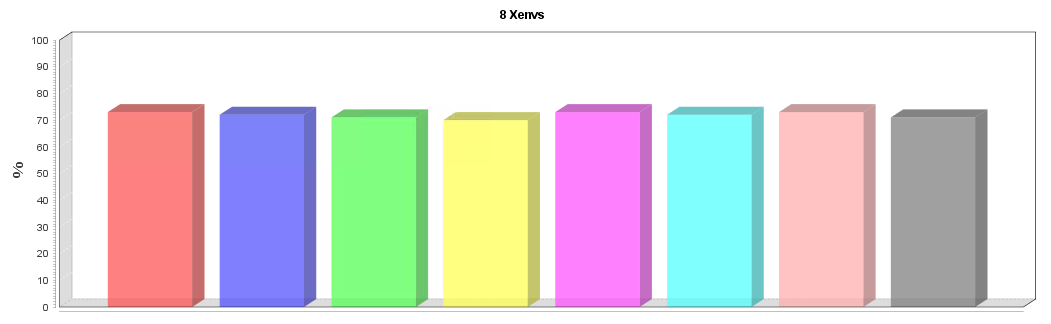
Specifically for the VDbench rhpct/whpct problem the good news is that it's easy to fix - VDbench provides a "hitarea" setting that controls the size of the area it uses to generate "hits". Increasing this setting from the default of 1MB to be an exact multiple of the number of cores in the array (ie, 4MB for a single brick, 8MB for a dual bricks, etc) will spread the load evenly across all storage controllers, whilst still being a small enough number to basically guarantee a cache hit.
The same test as above, only with hitarea set to 8MB shows a much more balanced result, and a higher overall IOPS rate with lower latency :
VDbench has another option that triggers this imbalance, "hotband", however this option doesn't have such a simple workaround, and more importantly appears to be fundamentally broken in that it doesn't act as is described in the documentation - but that's a topic for another day...