VMware Queue Depths and Conflicting Worlds
One of the more confusing storage-related settings in VMware is the "SchedNumReqOutstanding" setting. In versions up to and including ESX 5.1 this was a global setting for all LUNs. From 5.5 on it because a per-LUN setting controlled with the 'esxcli storage core device set --sched-num-req-outstanding' (or just -O) command.
Most people presume that this setting controls the number of outstanding requests for each LUN, and whilst that's close to correct, it's actually more complex than that.
As of ESXi 6.0, the "esxcli storage core device list" will show both the "device max queue depth" and this setting separately, with it's full name which is "No of outstanding IOs with competing worlds" :
naa.60000970000197800380533030303445
Display Name: EMC Fibre Channel Disk (naa.60000970000197800380533030303445)
[...]
Device Max Queue Depth: 128
No of outstanding IOs with competing worlds: 32
So what are "competing worlds"? Lets show it with an example...
I setup 2 guests on the same ESXi host. Each guest was running Linux and had a second virtual disk assigned from a datastore which was created on the LUN shown above.
On the first guest I configured Vdbench to generate around 100K IOPS, 32KB block size, 50/50 read/write, which it achieved with an average latency around the 0.75ms-0.81ms range (not bad for a single vmdk disk doing 100K IOPS and over 3GBytes/second!) :

On the second guest I started a much smaller Vdbench run - 10 seconds of generating only 2,000 IOPS, 8KB, 50/50 read/write. Given that we're already generating over 100K IOPS of much larger block size traffic, this additional 2000 IOPS should be little more than noise - but the impact on Vdbench running on the first host was significant :
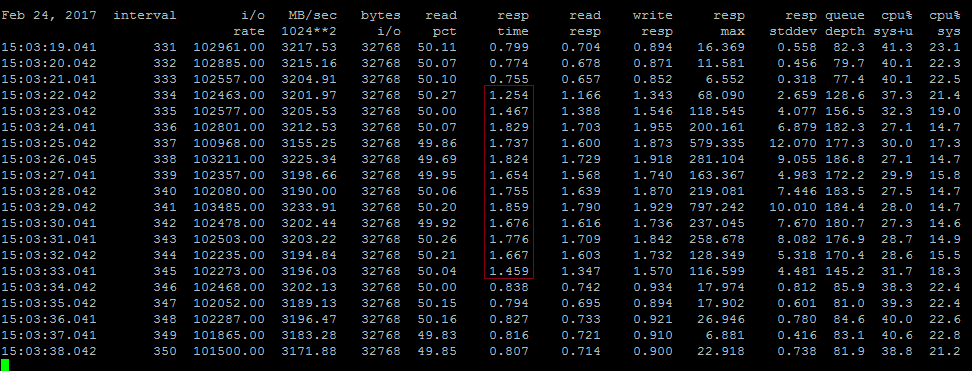
Although it still had no trouble sustaining ~100K IOPS, you can clearly see that for around 12 seconds latency was significantly higher - jumping from our previous ~0.8ms up to around 1.8ms.
Seemingly a 2% increase in total IOPS has managed to over double the latency of the storage.
In order to see what's really going on here we need to fire up esxtop, and specifically the 'disks' view (accessed by pressing 'u')
With only the single guest generating traffic, the esxtop output was :

The three important columns here are DQLEN (the Device Queue LENgth), ACTV (the number of active IOs) and QUED (the number of IOs queued within VMware).
DQLEN matches the Device Max Queue Depth shown in the esxcli output above. ACTV shows that we've got ~50 IOs outstanding to the physical storage, and as that's less than the device queue length we've got no IOs queued within VMware.
However the same output whilst running Vdbench on both guests shows something very different :

The DQLEN has dropped down to 32 rather than it's previous 128. Given that with one guest we were generating an active queue of ~50, it's not surprising that the number of active IOs is hitting the now maximum of 32, and thus we're seeing further IOs start to queue within VMware (QUED of 29). The restrictive DQLEN value is causing things to backup, and not surprisingly that additional queuing is causing our latency to increase.
So why did the DQLEN reduce down to 32? As you have probably already guessed, the "No of outstanding IOs with competing worlds" setting has come into effect. "competing worlds" in this context refers to multiple guests within the same VMware host accessing the same device at the same time. With only one guest generating IO to the LUN, this setting did not come into play - but the moment the second host started generating more than a background amount of IO then we had "competing worlds", and this setting came into effect. Once the second host stopped generating traffic, the DQLEN returned to it's normal 128, and thus latency dropped once again.
Increasing the "No of outstanding IOs with competing worlds" setting to be the same as the HBA queue depth and re-running the test gives results much more like what you'd expect - latency remains largely unchanged through the entire 10 seconds of the second guest generating traffic.
Note that whilst it is possible in most versions to set this value to a number higher than the Max Queue Depth, it will not have any effect - the DQLEN will never be increased above the Max Queue Depth value. As of ESXi 6.5, attempting to set it to higher than the queue depth value will return an error.